How to Build an AI Agent That Monitors Web Data Without Hallucinating
Stop feeding raw HTML dumps to your LLMs. Learn how to connect Gluedly to OpenAI and LangChain to build context-aware AI agents that run on clean, reliable data structures.
Product updates, guides, and insights.
Stop feeding raw HTML dumps to your LLMs. Learn how to connect Gluedly to OpenAI and LangChain to build context-aware AI agents that run on clean, reliable data structures.
Meta goes to extreme lengths to protect its DOM. Here is how our engineering team survived weeks of "DOM archaeology" to build an experimental, login-free Facebook group scraper—and the architectural breakthroughs that made it work.
Scraping shouldn't feel like a guessing game. This week, we launched smarter, step-by-step credit checks so you only pay for the pages that actually run. Plus, we’ve added an on-demand Manual Mode to stop overnight credit drains, and upgraded our mapper so modern JavaScript sites actually load with full styling—no more broken wireframes.
Gluedly now guides new users inside the app: interactive tours from the dashboard through page setup to XPath mapping, with preview clicks that create fields automatically and a more reliable styled embed preview.
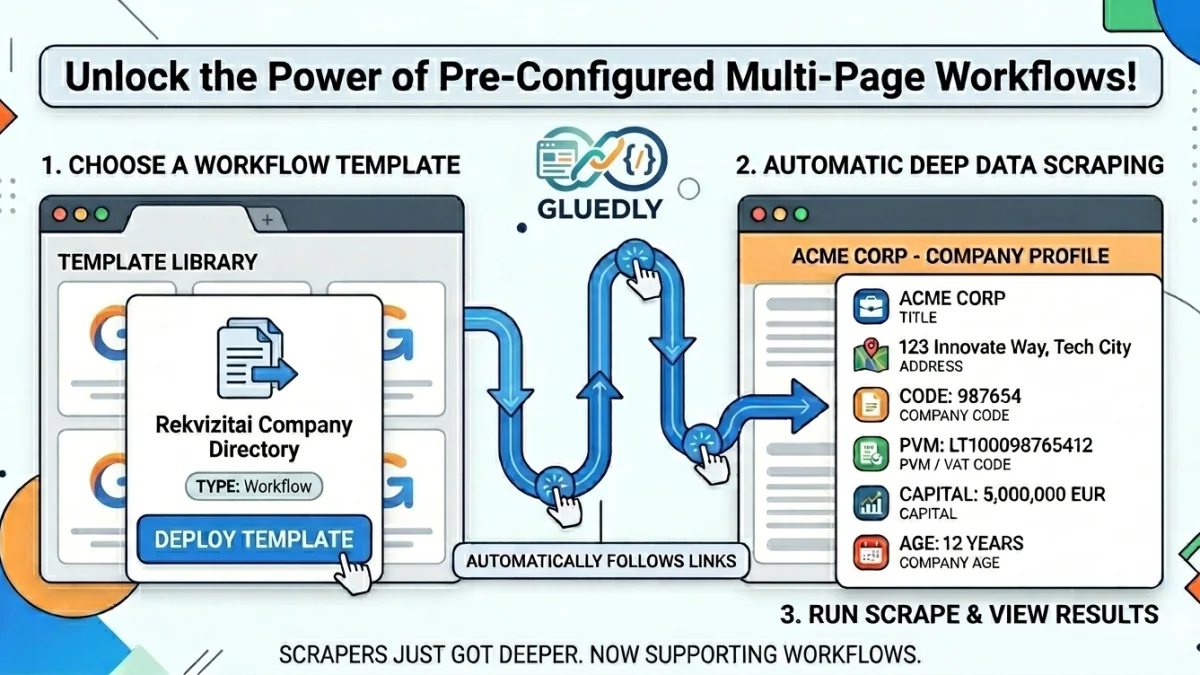
Deploy list → detail scrapers from the Template Library, manage workflow blueprints in admin, and start from a new Rekvizitai company directory template.
Every scrape used to mean a noisy webhook, forcing you to waste time filtering out duplicates in Zapier or Make. With our new conditional webhooks (data.changed), you can now choose exactly which fields matter—like price or inventory status—and only get pinged when those specific values move.
Stop stitch-building datasets by hand. Our brand-new Multi-Stage Workflow Scraping feature automatically connects product lists to detail pages, runs deep crawls in parallel, and merges your data instantly.
We fixed Elements Mapper add/remove sync, added row-container XPaths for list scraping, queued preview refetch with loading UI, and improved Pages enable/disable plus scrape queue visibility and worker shutdown.
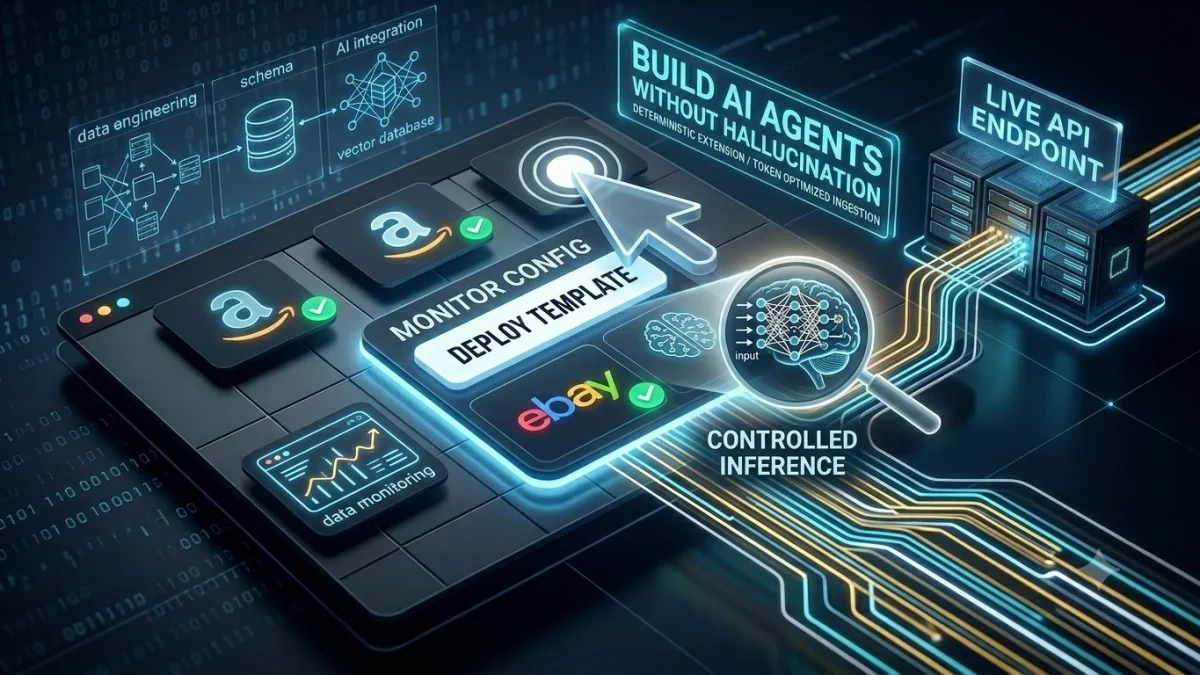
Learn how deploying pre-mapped blueprints for Amazon, eBay, and RAG ingestion pipelines eliminates configuration fatigue and gets you structured data instantly.
What are the benefits of one-click scraper blueprints?
Pre-mapped scraper templates allow teams to deploy production-ready web data pipelines for platforms like Amazon or eBay in under a minute. By leveraging AI-assisted selectors and pre-structured data models, you skip setup fatigue and stream structured JSON directly to your backend or RAG ingestion engine instantly.
Hidden costs and endless maintenance are the silent killers of custom scrapers. Learn how moving to a managed, success-only pipeline keeps your data flowing and your proxy budget safe.
Discover how dedicated concurrency lanes let you run automated price checks every 60 seconds smoothly without crashing your servers.
How do you scale automated competitor price monitoring to 60-second heartbeats?
Stop wasting your OpenAI token budget on messy HTML. Learn how feeding structured, noise-free JSON context directly into your vector store drops costs by 95% and eliminates model hallucinations.